
Taktikgespräche: Spielanalyseteam (SAT)
In der schnellen Welt von TFT, die sich ständig weiterentwickelt, spielt eine Gruppe von Helden, die als SAT (Spielanalyseteam) bekannt ist, eine entscheidende Rolle hinter den Kulissen. Die Mission dieser Helden besteht darin, einen Beitrag zur Spielbalance und zum Set-Design zu leisten, indem sie schon vor der Veröffentlichung eines Sets bis zu dessen letzten Patch sicherstellen, dass die Spieler eine optimale Gameplay-Erfahrung machen können.
Kurz und bündig:
- Das SAT ist ein relativ neues Team, das aus ehemaligen Analytikern, Trainern und Profis besteht, die in TFT aktuell alle die Meister-Klasse oder höher erreicht haben.
- Das SAT ist dafür verantwortlich, das Design während der frühen Entwicklungsphase eines Sets zu validieren … und zwar während einer sehr frühen Phase, in der noch nicht einmal Spieltests durchgeführt werden können.
- Dabei nutzt das SAT Simulationen, Datenanalysen und Spieltests, um sicherzustellen, dass die Spieler bereits an Tag eins eines Sets positive Erfahrungen machen, doch damit endet die Arbeit des Teams noch lange nicht. Das Team hilft auch bei der Live-Spielbalance, indem es durch seine eigene Erfahrung und Simulationen Kontext zur Verfügung stellt.
- Obwohl das SAT bereits an „Runeterra – Erneuerung“ und sogar „Glitch-Alarm!!“ gearbeitet hat, ist es aktuell zum ersten Mal vollständig in die Entwicklung eines Sets – unseres zehnten Sets – involviert.
Das sind die Mitglieder des SAT
Das SAT ist eine bunte Mischung aus talentierten Personen, die alle über einzigartige Hintergründe und Expertisen verfügen. Doch trotz der vielseitigen Hintergründe haben alle Mitglieder des Teams etwas gemeinsam: ihr Können in TFT. Jeder SATler (darf ich sie so nennen?) hat einen Rang zwischen Meister und Herausforderer – womit sie alle zu den besten 0,5–2 % aller Spieler gehören. Doch das ist noch nicht alles, denn die SATler haben neben der Tatsache, dass sie zu den besten TFT-Spielern der Welt gehören, noch mehr zu bieten. Lernen wir sie also kennen!
Iniko ist das neueste Mitglied des Teams. Er ist ein ehemaliger TFT-Profi, der mehrmals den begehrten 1. Rang belegen konnte. Inikos umfangreiches Wissen über das Spiel und Einblicke aus der Perspektive eines Profi-Spielers sind wertvolle Bereicherungen für das Team.
Victor stieß aus dem SAT von VALORANT zum brandneuen TFT-Team. Victor hat in den jeweiligen Spielen „Radiant“ und die Herausforderer-Klasse erreicht und belegte den 1. Rang in Hearthstone. Mit seinen unterschiedlichen Erfahrungen innerhalb der Gaming-Branche versucht Victor, TFT zu einer spaßigen und zugänglichen Erfahrung für alle zu machen.
Brian stammt aus dem SAT von Wild Rift und stieß auf der Suche nach einer neuen Herausforderung nach dem Erreichen von Rang 1 in WR zu TFT. Brian stößt mit seiner ganzen Expertise und all seinen Erfahrungen im Bereich der Qualitätssicherung zu dem Spiel, das ihm am meisten am Herzen liegt (dabei handelt es sich übrigens um das Spiel mit dem Pinguin mit dem Holzschwert).
Zu guter Letzt wäre da noch David Lim, der uns durch den Rest des Artikels führen wird – danke, David. David betrat die Gaming-Szene als Trainer für Organisationen wie Team Liquid, Clutch Gaming, XL Esports und FlyQuest in der LEC (LOL European Championship) und LCS (League Championship Series). Er stießt zum SAT, als es sich noch exklusiv mit League of Legends befasste. Nach der Veröffentlichung von TFT wuchs jedoch seine Leidenschaft für das Spiel und als er die Möglichkeit erhielt, das SAT für TFT zusammen mit Dave Park anzuführen, ergriff er die Gelegenheit begeistert beim Schopf. Okay, nun wird dich David durch einen Tag im Leben des SAT führen.
Das SAT während eines Sets
Danke Rodger, die täglichen Aufgaben des SAT hängen stark von der jeweiligen Phase der Set-Entwicklung ab.
Bevor die Spieltests beginnen können, ist das SAT für die Validierung des Designs verantwortlich – während dieser Phase vergleicht das Team die neuen Inhalte mit unseren übergreifenden Set-Standards für Einheiten, Attribute, Augmentierungen und andere Dinge. In diese Arbeit fließt eine Menge mit ein, aber hier ist eine Übersicht über die allgemeinen Komponenten, die sich das Team ansehen muss, bevor die Ingenieure damit beginnen können, das Design auf dem Papier in eine spielbare Version zu verwandeln:
- Der Kampf muss befriedigend, spannend und relevant sein
- Der Kampf muss intuitiv und verständlich sein
- Die Attribute müssen interessant sein und anstrebenswerte Schwellen aufweisen
- Es muss sowohl große vertikale als auch flexible (horizontale) Attribute geben
- Das Ausspähen anderer Spieler sollte ein Schlüssel zum Erfolg sein, die Kämpfe sollten jedoch nicht davon abhängig sein
Neben den allgemeinen Kampf- und Attributsstrukturen konzentriert sich das Team auf enger gesteckte Bereiche. Es beginnt damit, sich einzelne Einheiten und Attribute in frühen Entwicklungsphasen anzusehen und genau zu bewerten, um sicherzustellen, dass sie innerhalb des Rahmengerüsts des Spiels befriedigend sind und zu ihm passen. Ein entscheidender Aspekt dieses Prozesses ist die „Carry-Potenzial“-Überprüfung, mit der wir sicherstellen wollen, dass jede Carry-Einheit die Möglichkeit hat, mit den richtigen Kombinationen das Spiel zu tragen. Dazu nehmen wir beispielsweise einen 4-Gold-Carry wie Aphelios und analysieren, welche Komps und Einheiten am besten zu ihm passen. Diese Analyse des Carry-Potenzials für Aphelios hat beispielsweise zur aktuell beliebten Komp aus 3 Freljord-Einheiten und 4 Meisterschützen geführt.

Doch das „Carry-Potenzial“ ist nur ein Aspekt unserer Einheitenüberprüfung. Ein weiterer Teil der Zusammenarbeit mit dem SAT in der frühen Phase eines Sets besteht darin, die Design-Absichten an die Charakteristiken jeder Einheit anzupassen. Hierzu fragen wir die Designer, wie die Fantasie und Rolle für jede Einheit aussehen soll, um anschließend bei Spieltests, Simulationen (mehr dazu später) und Papierdesigns dafür zu sorgen, dass aus der Fantasie/Rolle ein funktionierender Teil des Sets wird, der intuitiv ist und Spaß macht. Hierbei berücksichtigen wird, wie jede Einheit ihre vorgesehene Rolle ausfüllt, weshalb wir Champions wie Sejuani auch anhand ihres Durchhaltevermögens und ihres Nutzens für die Komp und nicht anhand des Schadens durch ihre passive Fähigkeit (bei dem es sich um einen Bonus handelt, der sie zu einem 4-Gold-Tank anstelle eines 3-Gold-Tanks macht) bewerten.
Während der Designphase bekommen die Augmentierungen eine ähnliche Behandlung vom SAT. Wir verbringen viel Zeit damit, zu versuchen, Augmentierungen mithilfe von Gedankenexperimenten und Simulationen optimierter Kombinationen, die zu Balanceproblemen führen können, kaputtzumachen (es wird immer gute Kombinationsmöglichkeiten für Augmentierungen geben, bei denen starke Synergien entstehen – wir wollen aber sicherstellen, dass diese Synergie nicht den Erfolg von anderen Kombinationen verhindert). Außerdem versuchen wir, sicherzustellen, dass die Augmentierungen sowohl in Hinblick auf ihre Flexibilität (einige eignen sich eher für ganz bestimmte Komps, während andere einen allgemeineren Nutzen haben) als auch auf ihre Komplexität („Chaotischer Geist“ und „Blitzentscheidung“ sind gute Beispiele für komplexe Augmentierungen, die durch einfachere Augmentierungen wie „Tonnenweise Werte!“ oder „Aufstieg“ ausgeglichen werden müssen) abwechslungsreich genug sind.
Die Augmentierungen sind eine komplexe Machtquelle in TFT. Sie können Zugang zu mächtigen Attributsschwellen (wie Leere 8 oder Piltover 6) gewähren, die Art der Zusammenstellung einer Komp („Anders Gebaut“, „Doppelter Ärger“) verändern oder Regeln aufbrechen, die wir im Laufe der TFT-Sets gelernt haben („Infernalischer Vertrag“, „Grausamer Pakt“, „Risikofonds“). Da es so viele komplexe Machtquellen gibt, hilft das SAT auch dabei, sicherzustellen, dass jede davon – vor allem die krasseren Beispiele – über angemessene Balancehebel verfügt. Nehmen wir zum Beispiel die Augmentierung „Uralte Archive“, die „Wälzer der Attribute“ und etwas Gold gewährt. Wenn der Vorteil durch das Emblem irgendwann zu gering wird, können wir den Spielern, die diese Augmentierung auswählen, mehr Gold gewähren – und sollte der Vorteil zu groß werden, können wir jederzeit auch das genaue Gegenteil tun. Zu guter Letzt ist das SAT auch dafür verantwortlich, bestimmte Augmentierungskombinationen auf die schwarze Liste zu setzen. Wenn du in Phase 2–1 beispielsweise „Risikofonds“ auswählst, solltest du in Phase 3–2 nicht „Die Reichen werden reicher+“ auswählen können. Im Fall von „Runeterra – Erneuerung“ mussten wir auch einige Augmentierungen in Kombination mit bestimmten Portalen auf die schwarze Liste setzen – schließlich ist es nicht besonders spaßig, wenn deine Gegner nach dem Durchschreiten des Targon-Portals „Grausamer Pakt“ auswählen können, der Beute gewährt, sobald das Leben des Taktikers auf 40 sinkt, oder?
Wie zuvor bereits angedeutet, führen wir zu jeder Phase der Entwicklung eines Sets jede Menge Simulationen durch. Für diese Simulationen lassen wir ideale (oder nahezu ideale) Teamzusammenstellungen gegeneinander antreten. Und damit diese Simulationen so umfangreich wie möglich ausfallen, nutzen wir Spielfeld-Strings oder vorgefertigte Spielfelder im späten Spielverlauf, die das Team erstellt, um bestimmte Komps für den mittleren bis späten Spielverlauf zu repräsentieren. Für „Runeterra – Erneuerung“ erstellte das Team 82 mögliche Spielfelder im späten Spielverlauf in Form von Strings, um die Simulation möglichst effizient zu gestalten. Dank dieser 82 klar definierten Armeen können wir noch vor der Veröffentlichung eines Sets auf der PBE sachkundige Entscheidungen in den Bereichen Balance und Design treffen. Mithilfe dieser Strings können wir auch Anpassungen vornehmen, um bestimmte Faktoren einer Komp (Augmentierung versus Augmentierung, Einheit versus Einheit, Gegenstand versus Gegenstand) zu isolieren und ihre Stärke zu vergleichen. Simulationen spielen bei unserer Arbeit eine entscheidende Rolle, da wir dank ihnen verschiedene Zusammenstellungen testen und ihre Stärke genauer einschätzen können, als es bei reinen Datenanalysen oder Spieltests der Fall wäre. Das bedeutet aber leider auch, dass wir viel Zeit damit verbringen, in Simulationsumgebungen gegen uns selbst zu spielen. Da diese Strategie bisher jedoch gut funktioniert hat, werden wir dabei bleiben – auch wenn wir uns manchmal sehr einsam fühlen!
Doch die Spielfeld-Strings wären ohne den Kontext der theoretischen Stärke-Frameworks bedeutungslos. Dieses Framework hilft uns dabei, sicherzustellen, dass Zusammenstellungen mit ähnlichen Kosten und einem ähnlichen Maß an Zugänglichkeit auch ähnlich stark sind und dadurch ein faires und ausgeglichenes Gameplay ermöglichen. Hier sind ein paar Beispiele für dieses theoretische Framework:
- Spielfelder, die nur aus 1-Gold-Einheiten mit drei Sternen bestehen, sollten schwächer sein als Spielfelder, die nur aus 4-Gold-Einheiten mit zwei Sternen bestehen
- Spielfelder, die nur aus 2-Gold-Einheiten mit drei Sternen bestehen, sollten gleich stark sein wie Spielfelder, die nur aus 4-Gold-Einheiten mit zwei Sternen bestehen
- Spielfelder, die nur aus 3-Gold-Einheiten mit drei Sternen bestehen, sollten stärker sein als Spielfelder, die nur aus 4-Gold-Einheiten mit zwei Sternen bestehen
Die Spielfeld-Strings, Stärke-Frameworks und Simulationen sind nur einige der Werkzeuge, die wir vor allem in den Phasen vor der Veröffentlichung auf der PBE nutzen. Sobald ein Set auf der PBE veröffentlicht wurde, können wir auf einen wesentlich größeren Wissenspool zugreifen … große Spieldaten.
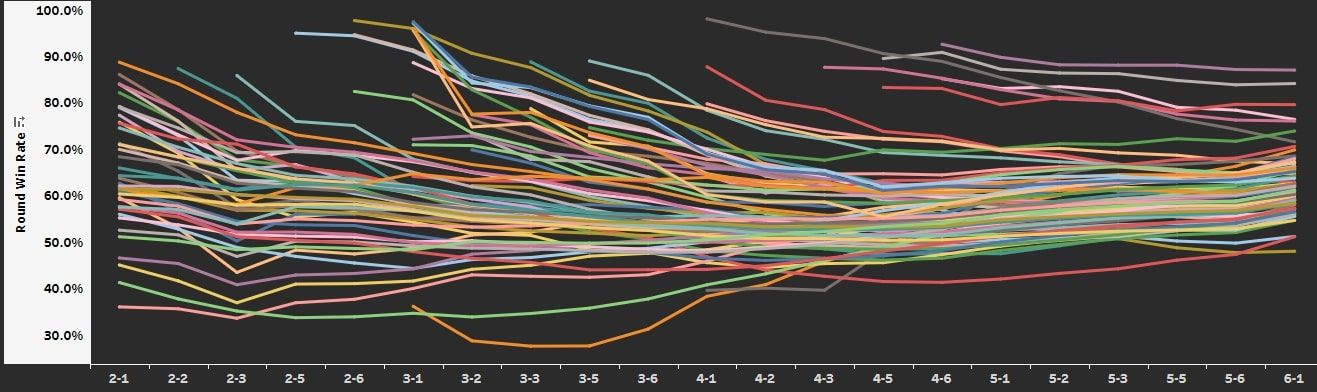
Die PBE versorgt uns mit einer Menge Daten, anhand derer wir sachkundige Entscheidungen treffen können. Wir sehen uns Daten an, die wir anschließend durch unser eigenes Gameplay (wie spielen wirklich viel) und Simulationen testen oder kontextualisieren, um Änderungen für die PBE oder die Live-Server vorzuschlagen.
Dazu sehen wir uns Dinge wie das LP-Delta an, das den Unterschied beim LP-Zuwachs oder -Verlust beim Aktivieren bestimmter Einheiten oder Attribute misst, befassen uns aber auch mit Dingen wie Siegesraten pro Runde in Prozent und Schnappschüssen täglicher Metaspiele. Diese datengetriebene Herangehensweise sorgt zusammen mit unserem tiefen Verständnis für die Feinheiten des Spiels als Spieler, Profis und Analytiker dafür, dass wir mit jedem Patch sachkundige und wirkungsvolle Anpassungen vornehmen können.
Das SAT – damals und heute
Wenn man auf die Erfolge des SAT zurückblickt, zeichnen unser Wachstum und unser Wandel im Laufe der Sets ein faszinierendes Bild. Kurz nach der Gründung – während „Monsterüberfall!“ – versuchte das Team, Herausforderungen bei der Übermittlung von Feedback und dem Aufbau eines nahtlosen Feedback-Kreislaufs zu überwinden. Als wir uns das erste Mal mit TFT befassten, hatten wir drei Mitglieder, die sich in den Dschungel wagten – was bei Riot bedeutet, dass Mitglieder eines Teams vorübergehend zu anderen Teams wechseln, um zu sehen, wie diese arbeiten (du kannst dir das Ganze wie eine Art Praktikum vorstellen). Wir führten sehr oberflächliche Simulationen und Design-Feedback-Runden durch, ohne zu wissen, wie und wie häufig wir Feedback am besten übermitteln sollten und wie es aussehen sollte. Trotz unserer Expertise als Einzelpersonen waren wir uns nicht sicher, welche Art von Feedback für die Designer nützlich wäre.
Schlussendlich gewöhnten wir uns jedoch an das Tempo des TFT-Entwicklungszyklus – das unglaublich hoch ist. Ich habe gehört wie ein Designer Folgendes sagte: „Wenn die Videospielentwicklung ein Zug wäre, der aus dem Bahnhof fährt und langsam Tempo aufnimmt, während Passagiere (Angestellte) einsteigen, dann wäre TFT ein Zug, der mit Höchstgeschwindigkeit unterwegs ist, durch den Bahnhof schießt und sich in drei unterschiedliche Realitäten aufteilt, weil er die Lichtgeschwindigkeit durchbrochen hat und von uns nicht mehr wahrgenommen werden kann.“ Du kannst dir sicher vorstellen, was passiert, wenn du versuchst, auf diesen Zug aufzuspringen – es wird in jedem Fall eine wilde Fahrt. Doch dank eines starken Fokus auf Prozessverbesserungen konnte das SAT schnell große Fortschritte beim Bereitstellen von Feedback und Analysen für die Design-Teams machen.
Bei „Runeterra – Erneuerung“ war das SAT zum ersten Mal in den Feinschliff des Set-Designs involviert. Wir wollten wesentlich stärker involviert sein und helfen, besser ausbalancierte Sets zu veröffentlichen, die viele verschiedene Komps und Erfolgsstrategien zulassen. Wir sind stolz auf die Arbeit, die wir bei der Überprüfung der neuen Augmentierungen geleistet haben, und die Feinabstimmung unseres Simulationsprozesses, über den ich bereits gesprochen habe. Wir haben jeden Tag Simulationen durchgeführt und den Designern zweimal pro Woche Berichte geschickt, um ihnen dabei zu helfen, die Zahlen bis zum letzten Tag vor der Veröffentlichung auf der PBE anzupassen. Und das hat zum Großteil gut funktioniert. „Runeterra – Erneuerung“ wurde ohne Aktualisierung zur Wochenmitte (die manchmal auch als B-Patch bezeichnet wird) vor Patch 13.13 veröffentlicht und zum Zeitpunkt des Verfassens dieses Artikels (Ende von Patch 13.12) führen viele verschiedene Komps zum Erfolg. Das bedeutet aber nicht, dass es mit dem Metaspiel von 13.12 keine Probleme gibt – es gibt nämlich sehr wohl welche (Zekes Herold). Doch da es bei der Veröffentlichung eines Sets jede Menge zu beachten gilt, ist die Veröffentlichung von „Runeterra – Erneuerung“ für uns im Vergleich zu den Veröffentlichungen vorheriger Sets (Drachenprophet-Nunu von „Drachenreiche“ oder Aktualisierungs-Vayne von „Abrechnung“) ein Erfolg.

An dieser Stelle ist es wichtig, zu erwähnen, in welchen Bereichen wir erfolgreich waren und in welchen wir uns noch verbessern können. Wie ein gewisser Balance-Designer, den du vielleicht kennst, einst sagte: „Im Fall von TFT ist die Balance ein Prozess, kein Endpunkt.“ Und ich glaube, dieses abgewandelte Zitat von Mort ist vor allem dann erkenntnisreich, wenn man sich die Balanceanpassungen von TFT in der Vergangenheit und jetzt zusammen mit dem SAT ansieht. Vor dem SAT wurden 100 % der Balanceanpassungen basierend auf einer Kombination an Daten, Community-Einschätzungen (ja, sie wirken sich auf Entscheidungen aus) und unseren eigenen Spielerfahrungen vorgenommen – daher ist jeder TFT-Patch auch eine Art Balance-Zusammenarbeit und -Diskussion mit den Spielern, die im Laufe der Zeit neue Kombos entdecken und das Metaspiel definieren. Durch das SAT haben wir einen Vorsprung bei diesen Diskussionen – sie finden nach der Veröffentlichung eines Sets zwar weiterhin statt, aber wir hoffen, dass das Metaspiel bei der Veröffentlichung in einem wesentlich besseren Zustand ist. Bei der Veröffentlichung von „Runeterra – Erneuerung“ war das Metaspiel in einem besseren Zustand, doch wir wollen nicht nur bei der Vorhersage von Balanceproblemen immer besser werden, sondern auch beim Tempo.
„Runeterra – Erneuerung“ hatte bei der Veröffentlichung auf der PBE ein unheimlich hohes Tempo. Wenn wir bei TFT vom Tempo sprechen, meinen wir die Rate, mit der dein Spielfeld im Laufe der Zeit stärker wird. Wir hatten eine Vorahnung, dass es eine Inflation geben würde, weil die neuen Set-Mechaniken (die Regionsportale und Legenden) zur selben Zeit eingeführt wurden und beide Möglichkeiten boten, die Menge an Gold und ERF zu erhöhen. Dies führte gemeinsam mit über 100 neuen Augmentierungen zu jede Menge Gelegenheiten, schneller Gold oder höhere Stufen zu erhalten, was das Tempo des Spiels stark beschleunigte. Während sich Simulationen hervorragend eignen, um die Stärke des Spielfelds oder bestimmter Einheiten in festgelegten Situationen zu ermitteln, eignen sie sich für die Ermittlung des Spieltempos nicht so gut wie Spieltest. Deshalb werden wir in Zukunft rund um die Veröffentlichungen auf der PBE mehr von ihnen durchführen, um Facetten von TFT einschätzen zu können, die bei Simulationen nicht zum Tragen kommen. Wir haben sogar schon damit begonnen.
Das Team ist gerade voll mit den Arbeiten am zehnten Set beschäftigt und führt nun schon seit knapp drei Monaten Spieltests durch. Das ist das erste Mal, dass wir ein Set bereits so weit im Vorfeld der Veröffentlichung testen können, und wir konnten bereits einen großen Beitrag zur finalen Version des Sets liefern – was eine gute Sache ist, da TFT von Set zu Set mehr Variablen bekommt, und das kommende Set bildet dabei keine Ausnahme. Wir machen uns aber nicht nur mit den neuen Attributen, Einheiten und Mechaniken von TFTs zehnten Set vertraut, sondern arbeiten auch mit dem Set Design Lead Matthew Wittrock zusammen, um sicherzustellen, dass jede Einheit, jedes Attribut und jede Mechanik nicht nur die Designziele, sondern auch unsere Design-Validierungsvoraussetzungen, die ich bereits erwähnt habe, erfüllt.
Das zehnte Set ist das erste, auf das sich das SAT voll und ganz konzentrieren kann (neben dem Live-Betrieb). Bei „Runeterra – Erneuerung“ arbeiteten wir gleichzeitig an der Set-Aktualisierung für „Monsterüberfall!“ „Glitch-Alarm!!“ und halfen dem Live-Team, wo wir konnten. Doch jetzt, da wir auf einen Drei-Set-Zyklus umgestiegen sind, haben wir mehr Zeit für jedes einzelne Set, da diese eine längere Entwicklungsdauer haben. Du kannst dir hier das Update von Mort und Peter zum neuen Zeitplan ansehen. Durch die zusätzliche Zeit können wir mehr als generalisierte Überprüfungen und Gameplay-Validierungen vornehmen – wir können weitere Szenariosimulationen und Augmentierungskombinationen hinzufügen und testen, wie die neue Set-Mechanik mit dem Rest interagiert. Das ist ein Novum für TFT, und wir hoffen, dass das bereits bei der Veröffentlichung von „Runeterra – Erneuerung“ augenscheinlich war, wir freuen uns aber auch schon sehr, zu zeigen, was wir mit mehr Zeit pro Set zu TFT beitragen können!